
Apple がmacOS Tahoe 26.2でRDMA over Thunderboltを有効化しました。これにより、複数のMacをThunderboltケーブルで接続し、高速なAIクラスタを構築できるようになります。以前当ブログで紹介したexo やParallax のような分散AIフレームワークと組み合わせることで、自宅でも本格的なローカルAI推論環境が実現可能になりました。
RDMA over Thunderboltとは?
RDMA(Remote Direct Memory Access)は、ネットワーク経由でリモートマシンのメモリに直接アクセスする技術です。従来のTCP/IP通信と比較して、CPUを介さずにデータ転送できるため、低レイテンシと高スループットを実現できます。
従来のTCP/IP通信 vs RDMA
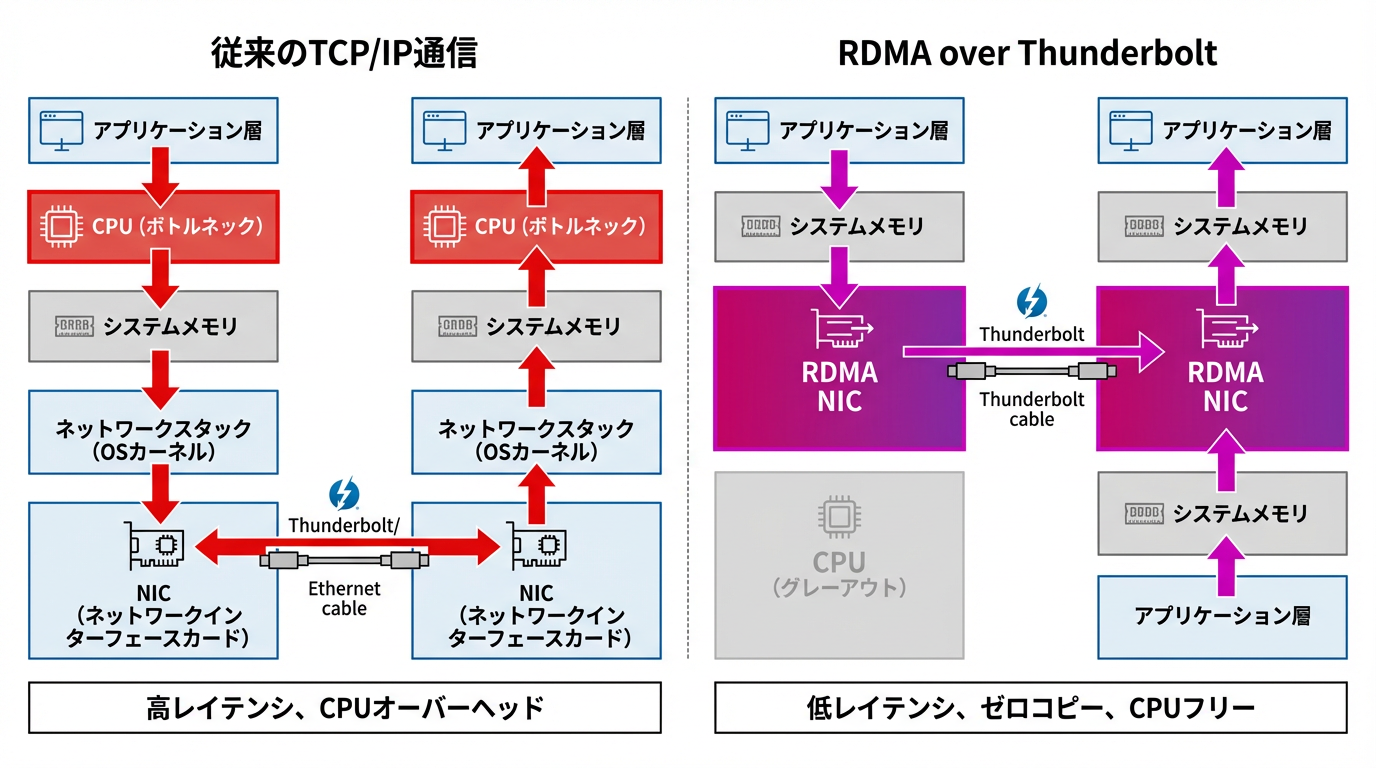
主な違い:
- 従来方式(左): CPUがデータコピーを仲介 → オーバーヘッド大、レイテンシ高
- RDMA(右): メモリ間で直接転送 → CPUフリー、ゼロコピー、レイテンシ最小
今回のmacOS 26.2では、この技術がThunderboltインターフェース上で利用可能になりました。Appleの公式リリースノート によると、主な特徴は以下の通りです:
- 低レイテンシ通信: CPUを介さないゼロコピー転送
- 高帯域幅: Thunderbolt 4で40Gbps、Thunderbolt 5で80Gbps
- テンソル並列処理のサポート: MLXでの高速分散推論が可能に
なぜこれが重要なのか?
パイプライン並列からテンソル並列へ
これまでexoなどの分散AIフレームワークでは、パイプライン並列(Pipeline Parallelism)を使用していました。これは、モデルの各レイヤーを異なるマシンに割り当てる方式です。
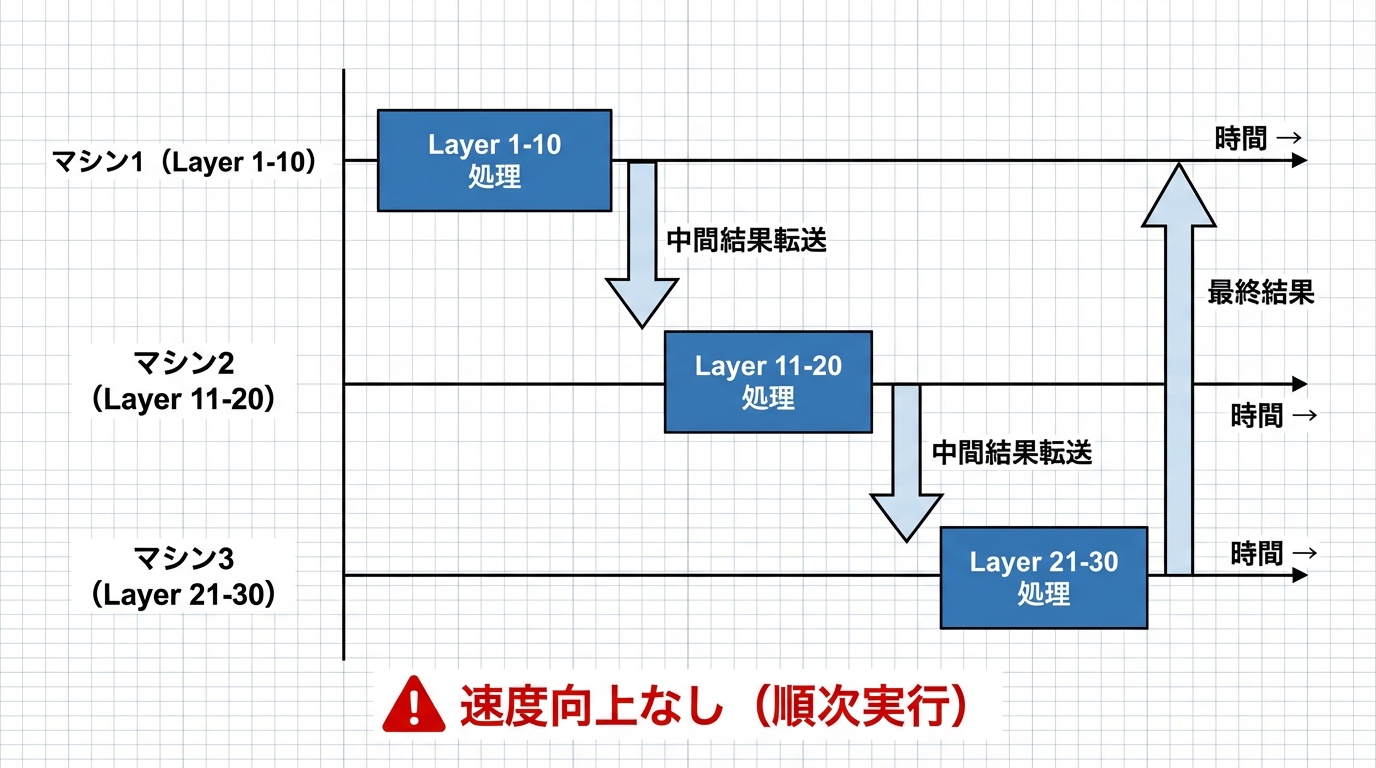
この方式では、1台のマシンに収まらない大規模モデルを動かせるようになりますが、推論速度の向上は期待できません。各マシンは順番に処理するため、最も遅いマシンがボトルネックになります。
一方、テンソル並列(Tensor Parallelism)は、各レイヤー自体を複数マシンに分割します:
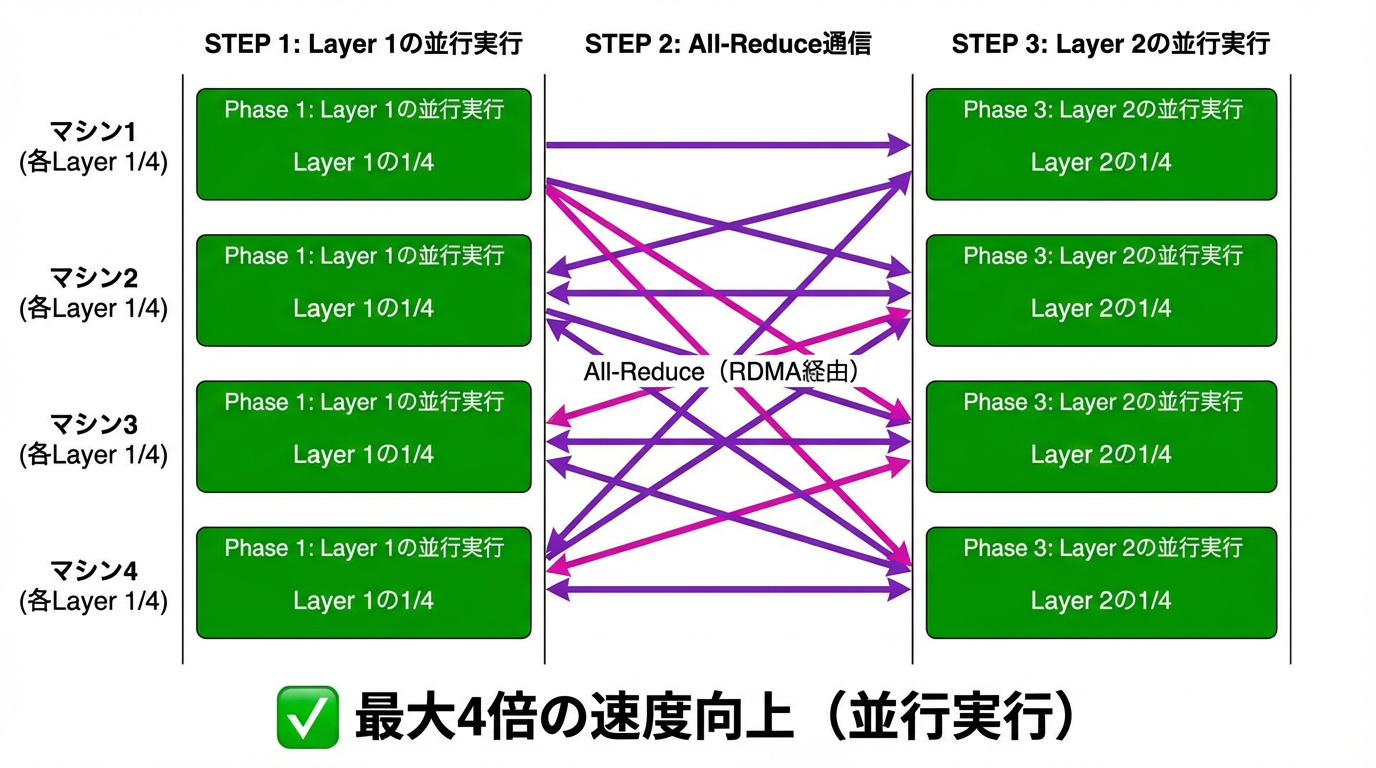
この方式では、N台のマシンで最大N倍の速度向上が見込めます。ただし、各ステップで頻繁な通信(all-reduce操作)が必要になるため、通信レイテンシが非常に重要になります。
MLXチームの実測値
MLX の開発者であるAwni Hannun氏がHacker Newsで共有した情報によると:
バッチサイズ1でのトークン生成(デコーディング)において、4台のマシンで最大3.5倍の速度向上を確認しています。メモリ帯域幅がボトルネックとなる処理では、モデルとKVキャッシュを4分割することで、各マシンが1/4のメモリアクセスで済むためです。
これは非常に実用的な数字です。従来のパイプライン並列では速度向上が見込めなかったのに対し、テンソル並列+RDMAの組み合わせで実際にスケールすることが確認されました。
必要な環境とセットアップ
ハードウェア要件
- Mac Studio M3 Ultra または同等のApple Silicon Mac(複数台)
- Thunderbolt 4/5ケーブル(高品質なものを推奨)
- フルメッシュ接続: 各マシンが他のすべてのマシンと直接接続
Mac Studioは6つのThunderboltポートを持つため、最大6-7台までのフルメッシュ構成が可能です。
ソフトウェア要件
- macOS Tahoe 26.2以降
- MLX / mlx-lm(最新版)
RDMAの有効化
RDMAはセキュリティ上の理由からデフォルトで無効になっています。有効化するには、リカバリモードで以下のコマンドを実行する必要があります:
| |
この設定は各マシンで個別に行う必要があります。
実際の構成例
2台構成(最小構成)
最もシンプルな構成です。2台のMac Studioを1本のThunderboltケーブルで接続します。
Mac Studio 1 (512GB) ←→ Mac Studio 2 (512GB)
合計: 1TB ユニファイドメモリ
この構成で、DeepSeek R1(671Bパラメータ)などの大規模モデルを実行できます。MLXチームは実際にこの構成でDeepSeek R1を動作させています:
4台構成(推奨)
より大規模なモデルや、速度向上を求める場合は4台構成がおすすめです。
Mac Studio 1
/ | \
Mac Studio 2 - Mac Studio 3
\ | /
Mac Studio 4
フルメッシュ構成では、各マシン間で直接通信できるため、all-reduce操作のレイテンシを最小化できます。
この構成で、Kimi K2 (1兆パラメータ)のような超大規模モデルも動作可能です:
コスト比較:Apple vs NVIDIA
技術コミュニティでの議論(Hacker News )から、$50,000での構成比較が興味深いです:
| 構成 | 容量 | 速度 | 特徴 |
|---|---|---|---|
| Apple M3 Ultraクラスタ | 3TB | ~15 t/s | 1兆パラメータ以上のモデルが動作可能 |
| NVIDIA RTX 6000ワークステーション | 384GB | >80 t/s | 400B以下のモデル向け、高速 |
Appleクラスタの強みは容量です。$50,000で3TBのユニファイドメモリを確保でき、超大規模モデルを動かせます。一方、NVIDIAは速度で優位ですが、VRAMの壁があります。
コミュニティの試算によると、同等の容量と速度を両立するには、$270,000のNVIDIA GH200クラスタが必要になります。Appleクラスタは、その18%のコストで87%の容量を提供します。
exo・Parallaxとの組み合わせ
(※2025年12月18日更新) exo のバージョン1.0でRDMA対応テンソル並列が正式にサポートされました。以下の表は更新後の対応状況です。
| ツール | 並列方式 | RDMA対応 | テンソル並列 |
|---|---|---|---|
| mlx-lm | パイプライン+テンソル | ✅ | ✅ |
| exo 1.0 | パイプライン+テンソル | ✅ | ✅ |
| Parallax | パイプラインのみ | ❌ | ❌ |
exo 1.0では、AppleのRDMA over Thunderbolt機能を直接活用し、テンソル並列処理を実装しました。4台構成で最大3.2倍の速度向上が実測されています。詳細は本記事末尾の「追記」セクションを参照してください。
一方、Parallaxは引き続きパイプライン並列のみで、独自の分散通信層(Lattica)を使用しているため、AppleのRDMA機能を直接活用することはできません。
ただし、これらのツールでも従来のThunderbolt Networking経由で分散推論は可能です。RDMAほどの速度向上は見込めませんが、大規模モデルを複数台で動かす基本的なユースケースには対応しています。
| |
クラスタが自動検出され、モデルがシャーディングされます。詳細は以前の記事 やParallaxとの比較記事 を参照してください。
注意点と課題
物理的な接続の安定性
Thunderboltケーブルは、サーバー用途としては物理的な安定性に不安があります。Jeff Geerling氏 (有名なホームラボ系YouTuber)がHacker Newsで指摘しているように:
- ポートの物理的な耐久性
- ケーブル品質による接続不安定
- ラックマウント時のケーブル管理
長期運用を考える場合は、ロッキング機構付きのケーブルや、OWC のThunderLokのような固定アダプタの使用を検討してください。
macOSのリモート管理
LinuxやWindowsと比較して、macOSのヘッドレス運用には課題があります:
- メジャーOSアップグレードにはGUIが必要
- SSH経由での完全な管理が困難
- MDMソリューションの導入が望ましい
クラスタ運用を本格的に行う場合は、Jamf などのMDMツールの導入を検討してください。
消費電力
意外なことに、消費電力は非常に低いです。MLXチームの実験では、2台のMac Studioで50W以下を実現しています。NVIDIAのGPUクラスタと比較すると、電力効率は圧倒的に優れています。
まとめ
macOS 26.2のRDMA over Thunderboltは、自宅でのローカルAI推論環境に大きな可能性をもたらします:
- テンソル並列が実用的に: 4台で3.5倍の速度向上
- 超大規模モデルの実行: 1兆パラメータ以上も可能
- コスト効率: 同等のNVIDIA構成の18%のコスト
- 低消費電力: 2台で50W以下
NVIDIAに依存しないローカルAI推論環境を構築したい方、プライバシーを重視する研究者・開発者にとって、Apple Siliconクラスタは現実的な選択肢になりつつあります。
MLXの公式テンソル並列サポートがリリースされ次第、実際に試してみたいと思います。
追記(2025年12月18日): exo 1.0正式リリース
本記事公開後、exo 1.0が正式リリースされました。本記事で紹介したRDMA over Thunderboltを活用したテンソル並列処理が実装され、4台構成で最大3.2倍の速度向上が実測されています。
詳細なベンチマーク結果、macOSネイティブアプリの提供、セットアップ手順については、続報記事「exo 1.0: RDMA over Thunderbolt 5で分散AI推論が最大3.2倍高速化 」をご覧ください。
参考リンク
- macOS Tahoe 26.2 Release Notes - Apple Developer
- MLX - Apple Machine Learning Framework
- mlx-lm - MLX Language Models
- exo - 分散AIクラスター
- DeepSeek公式サイト
- DeepSeek R1セットアップ手順(Gist)
- Kimi K2 - Moonshot AI
- Hacker Newsでの議論
- Jeff Geerling - YouTube
- OWC - Mac周辺機器
- exo公式サイト
- llama.cpp - LLM推論エンジン
- uv - Pythonパッケージマネージャ
- macmon - Apple Siliconモニタリングツール
- Jeff Geerling: 1.5TB VRAM on Mac Studio - RDMA over Thunderbolt 5
- 当ブログ過去記事:exoで分散AIクラスターを構築する
- 当ブログ過去記事:Parallax vs exo比較
- 当ブログ続報記事:exo 1.0のRDMA対応詳細