
Conflux の最初のリリースを出しました。これは、仕様駆動開発(先に仕様や変更の意図を定め、それに沿って実装と検収を進める開発スタイル)を前提に、AIコーディングエージェントの作業を並列に回し、実装・検収・アーカイブまで含めた開発フロー全体を前に進めるためのツールです。
最近は、Claude Code や Codex 、OpenCode のようなツールで「コードを書く」こと自体はかなり簡単になりました。一方で、実際の開発では仕様をどう持つか、複数の変更をどう安全に並行させるか、どこで受け入れ判定をするかの方が難しいです。
Conflux は、そこを埋めるために作りました。単発のコード生成ではなく、変更を積み上げながら一定規模の完成品を育てていくための、現実的なオーケストレーション層という位置づけです。

Conflux の見た目はこんな感じです。TUI(Text User Interface、ターミナル上で動くテキストベースのUI)として、change の進行状況や全体の流れを確認できます。
何を解決したかったのか
AIエージェントを開発フローに入れると、最初はとても速く見えます。しかし、少し大きいタスクになると、次の問題がすぐ出てきます。
- 仕様が曖昧なまま実装が進む
- 変更同士がぶつかる
- どこまで終わったか分からなくなる
- 実装したエージェントと検収するエージェントの役割が混ざる
- 人が常に張り付かないと流れが止まる
つまり、必要なのは「もっと賢い単体エージェント」だけではなく、複数の変更を流し続けるための運用の型でした。
Conflux では、この問題を次の考え方で整理しています。
- 仕様を先に持つ
- change ごとに独立した作業単位に分ける
- git worktree を使って並列に進める
- 実装役と受け入れ役を分ける
- 人が見ていない時間もフローを前に進める
Conflux の中身を一言でいうと
README では「spec-driven parallel coding orchestrator for AI agents」と書いています。日本語で言うなら、仕様駆動のAI開発を、並列実行と役割分離つきで回すオーケストレータです。
特に大事なのは、Conflux 自体が「最強の1モデルに依存するツール」ではないことです。特定ベンダー固定ではなく、用途に応じてエージェントを差し替えられる前提で設計しています。
これは個人的にかなり重要でした。実装は速いが雑なモデル、遅いが検収に強いモデル、CLI と相性がいいモデル、長文レビューが得意なモデルはそれぞれ違います。1つのモデルで全部やるより、役割を分けた方が実務では安定しやすいです。
どういう流れで使うのか
基本の考え方はシンプルです。
- 仕様や変更の狙いを整理する
- change ごとに作業を分離する
- Conflux が各 change を独立した worktree に割り当てる
- 実装を進める
- 受け入れ判定を行う
- 通ったものをアーカイブし、最終的なマージまで進める
ここで重要なのは、1 がただのメモ書きではないことです。Conflux は「先に実装して、あとから説明を足す」流れではなく、仕様や変更意図を先に置き、それを単位に実装を流す前提で設計しています。
Conflux では、このうち後半の 実装 → 受け入れ判定 → アーカイブ/マージ を反復可能なループとして回し続けます。多重Ralphループの図を見ると、この流れがイメージしやすいです。
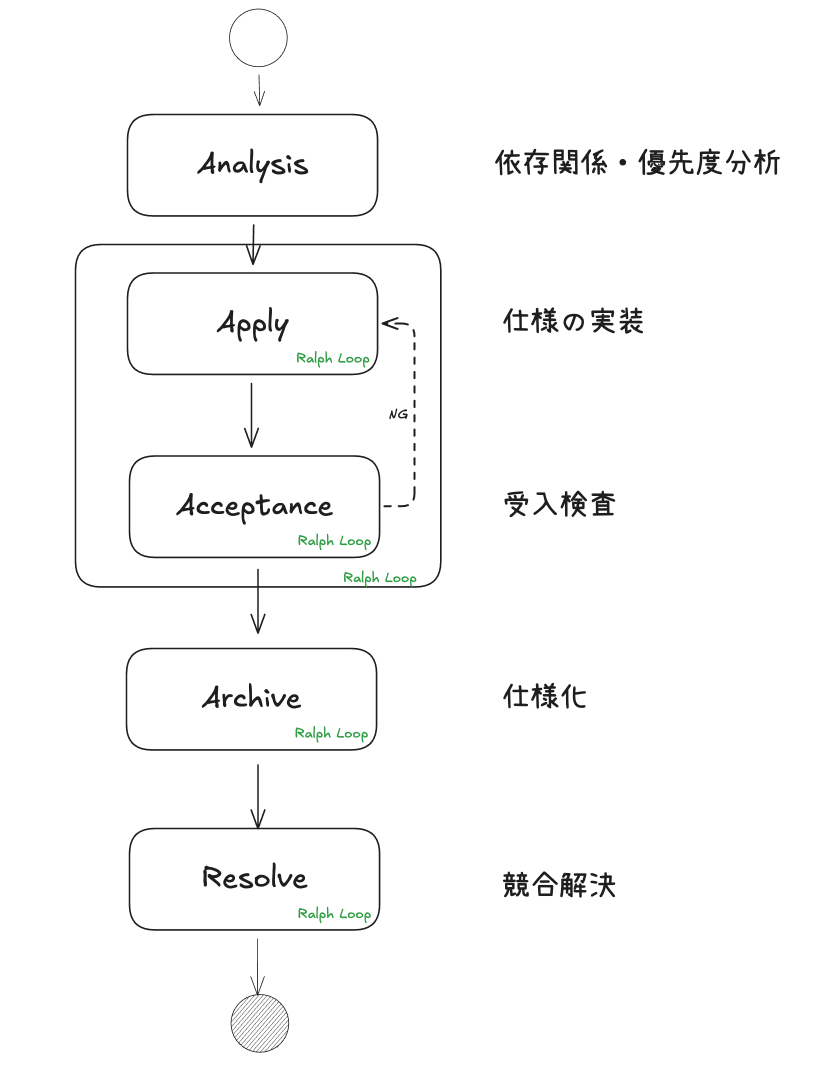
この図が表しているのは、1回実装して終わる直線的な流れではありません。実装結果を受け入れ判定し、通らなければ次の反復に回し、通ったものをアーカイブして前に進める、という継続的な開発フローです。
この流れのメリットは、1つの巨大なプロンプトに全部を押し込まなくていいことです。変更単位で文脈を小さく保てるので、LLM (大規模言語モデル)に渡すコンテキストも整理しやすくなります。
まず試す最小手順
以下は、Conflux をローカルで最小構成で試すための手順です。前提として、Rust
と cargo が使えること、そして手元に AI コーディングエージェントのCLIが1つ入っていることを想定します。
やることは3つです。
- Conflux をインストールする
- 設定ファイルを初期化する
- 実行を始める
| |
まずはここまでで十分です。cflx が起動すれば、最低限の導入確認は完了です。
ヘッドレス実行(画面なしで実行するモード)を試したい場合は、次のコマンドを使います。
| |
確認ポイントは単純です。
cflxで TUI が起動するかcflx initで設定ファイルの雛形が作られるかcflx runでフローが開始できるか
今回のリリースで特に大事な点
初回リリースの段階で、自分が重視したのは次の3点です。
1. 単発生成ではなく、フロー全体を扱うこと
「コードを書ける」だけなら、今は選択肢がかなりあります。ただ、実際に必要なのはその前後です。
- 仕様を定める
- 変更単位に分ける
- 並列に流す
- 検収する
- マージまで持っていく
この一連を扱わないと、実務ではすぐ手で運用する部分が増えてしまいます。Conflux はそこを最初から対象にしています。
2. 並列実行を前提にしたこと
AIエージェントは、1本ずつ順番に回すだけでも便利です。ただ、変更が増えると待ち時間が目立ちます。
そこで Conflux では git worktree を使って、change ごとに独立した作業領域を持てるようにしています。これにより、複数の変更を比較的安全に並列で進められます。
ただ、ここで言いたいのは「並列実行できること」だけではありません。並列実行そのものは今や珍しくなく、複数エージェントや複数タスクを同時に走らせる仕組みはいろいろあります。
少ないのは、その先です。つまり、並列に走った変更を受け入れ判定し、アーカイブし、最終的なマージまで持っていくところまでを、ひとつの開発フローとして扱う仕組みです。
もちろん、並列化すれば何でも速くなるわけではありません。依存関係の強い変更は順序制御が必要ですし、受け入れ判定の質も重要です。ただ、少なくとも「同じワークツリーで全部混ぜて事故る」よりは見通しが良く、さらにその後段まで含めて扱うのが Conflux の狙いです。
3. ベンダー固定にしなかったこと
これはかなり意図的です。AIツールの勢いが強い今、特定のベンダーや特定のプロダクトに密結合すると、運用の寿命が短くなりやすいです。
Conflux は、エージェントを交換可能な部品として扱えるようにしています。たとえば、実装は Claude Code、レビューや検収は別のモデル、という組み方もできます。
どんな人に向いているか
現時点で Conflux が特に向いているのは、次のようなケースです。
- 仕様駆動で開発を進めたい人
- AIエージェントに実装を任せつつ、人間は仕様と最終判断に集中したい人
- 複数の change を同時に回したい人
- 1回きりの生成ではなく、プロダクトを継続的に育てたい人
逆に、「とりあえず1ファイルだけ生成したい」「単純なコード補完だけ欲しい」という用途なら、Conflux はやや大げさです。その場合は、単体のエージェントCLIを直接使う方が早いと思います。
これから試すなら、どこを見るべきか
最初に見るなら、次の順番がお勧めです。
- README.ja.md で全体像を掴む
- QUICKSTART.ja.md で初回セットアップを進める
まずはローカルで cflx init と cflx を試して、「仕様を先に置き、変更を分けて並列に流し、検収しながら積み上げる」感覚が自分の開発スタイルに合うかを見るのが良いです。
まとめ
Conflux の最初のリリースを出しました。
自分が作りたかったのは、AIにコードを書かせるための単なるラッパーではありません。仕様を起点に、複数の変更を並列に回し、検収し、最終的な完成品まで前進させるための運用基盤です。
まだまだ育てていく段階ですが、仕様駆動と AI コーディングエージェントを実務の流れに乗せたい人には、かなり面白い土台になってきたと思います。OpenSpec はそのための現時点の実装手段の1つに過ぎず、将来的には別の表現や別の仕様記述レイヤに置き換わる可能性もあります。それでも、仕様を先に置くという考え方自体は残るはずです。興味があれば、まずはローカルで触ってみてください。