
最近注目を集めているオープンソースの分散AIクラスターソフトウェア exo を、手元のMacBook 2台を使って試してみました。本記事では、exoの概要、インストール方法、設定、そして実際の使用感について詳しく紹介します。
exoとは?
概要
exoは、家庭内にある複数のデバイスを統合し、AIクラスターとして利用できるソフトウェアです。以下のような特徴があります:
- 幅広いデバイスサポート: iPhone、iPad、Android、Mac、Linuxなど、多様なデバイスを活用可能。
- 高価なGPU不要: 既存のデバイスを活用し、AI推論を分散処理。
- 分散推論を簡単に実現: 高度なシャーディング技術で大規模モデルを効率的に動作。
- オープンソース: GPLv3ライセンスのもとで開発されており、自由に利用可能。
公式GitHubリポジトリはこちら: https://github.com/exo-explore/exo.git
使用したデバイス
今回の実験では以下の2台のMacBookを使用しました:
2021年モデル
- Apple M1 Max
- 64GB RAM
- macOS Sequoia 15.2
2024年モデル
- Apple M3
- 24GB RAM
- macOS Sequoia 15.2
exoのインストール
環境構築
1. GitHubリポジトリをクローンします
| |
2. Python環境を準備します
| |
3. 必要な依存関係をインストールします
| |
4. exoコマンドを確認します
| |
以下のようなメッセージが出続けるときには環境変数で抑制できます。
| |
| |
ユニファイドメモリの設定
Apple Siliconでは、メモリ割り当てを最適化することでパフォーマンスを向上させることができます。以下の手順で設定を行いました:
1. 現在の設定を確認
| |
2. 設定変更用のスクリプトを実行
exoリポジトリ内には、ユニファイドメモリの割り当てを最適化するための configure_mlx.sh というスクリプトが用意されています。このスクリプトを実行することで、GPU処理優先の設定に変更できます。
| |
注意: この設定はシステム全体に影響を与えるため、実行前に現在の設定を確認し、必要に応じて復元できるようバックアップを取ることをお勧めします。
3. 必要に応じて設定を元に戻します
| |
exoの使用方法
クラスタ構築
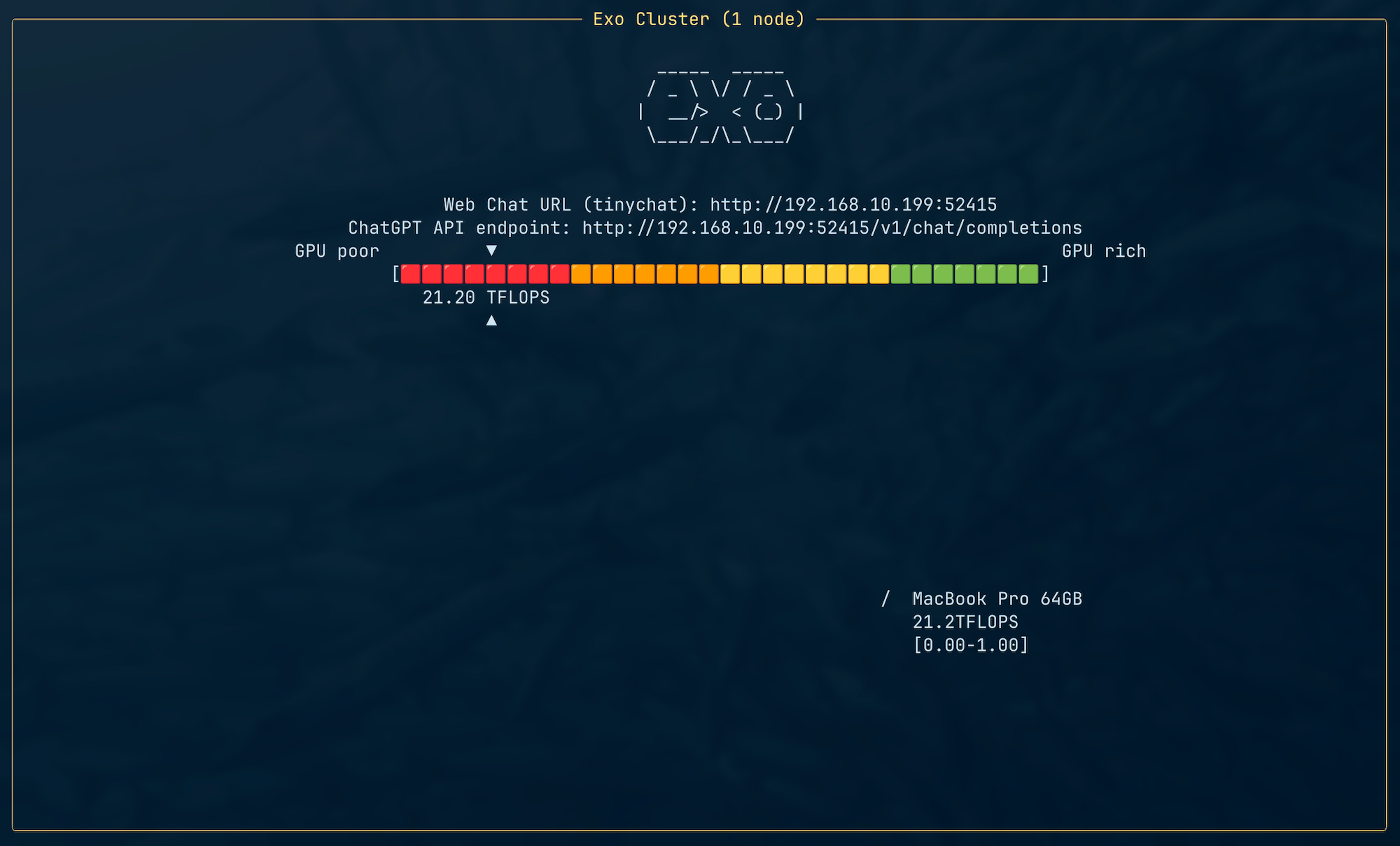
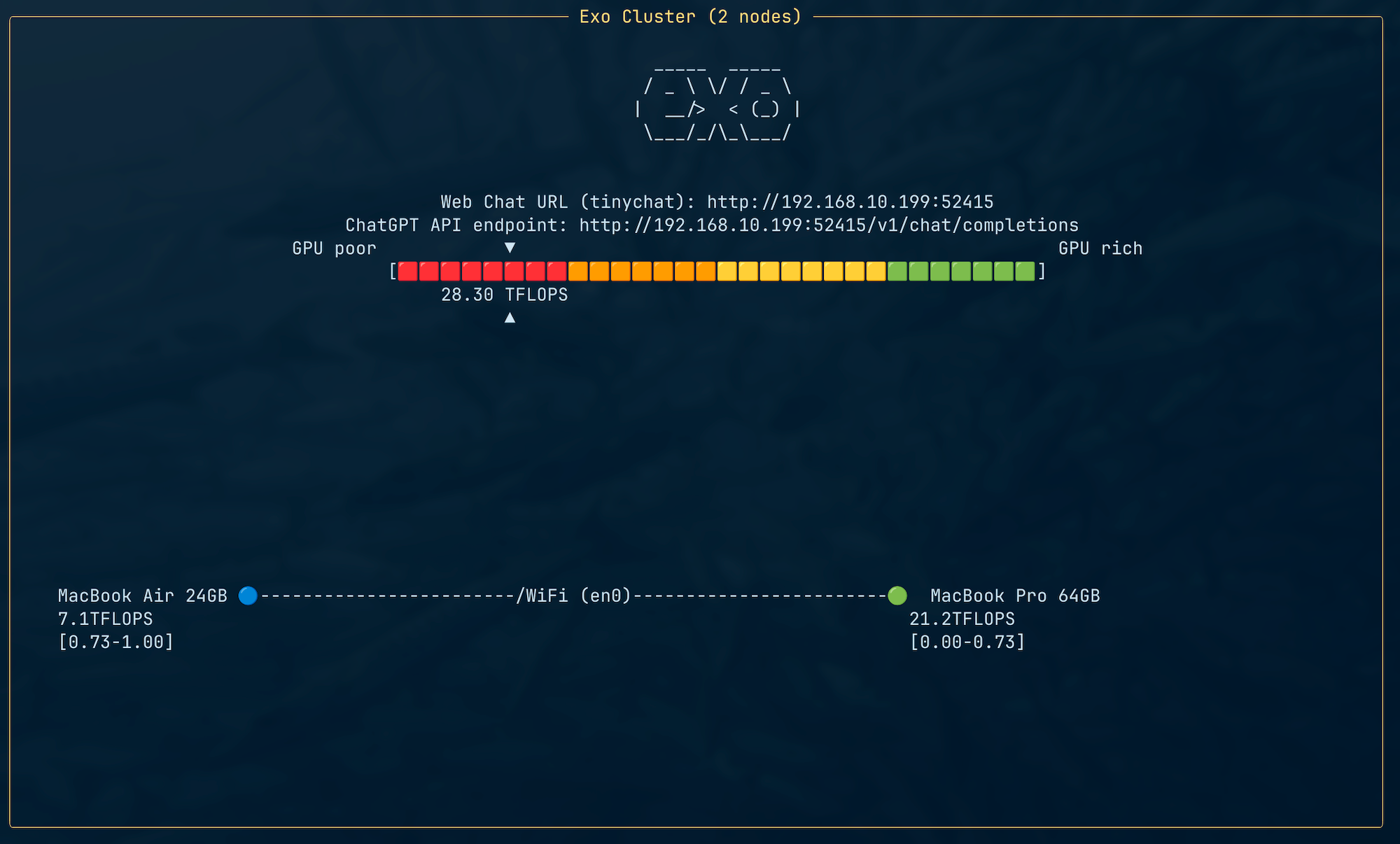
exoを起動すると、自動的に同一ネットワーク上の他のデバイスを検出し、クラスタに参加します。
| |
| |
4年前のM1の方が3倍速いことになっていますね。
クラスタのチャット画面はブラウザでアクセス可能です。URLは起動時に表示されます。
Webブラウザで http://127.0.0.1:52415/ を開いてみます。
モデルの選択とチャット
管理画面から利用したいモデルを選択します。モデルはクラスタ全体で分散してダウンロードされ、準備が整うとチャットが可能になります。
サポートされているモデルの一例:
- LLaMA: Meta AIの基盤モデル。
- LLaVA: 画像と言語を扱えるマルチモーダルモデル。
- Deepseek V2: 技術文書の生成に特化。
ただし、日本語でのチャットは現在文字化けすることが確認されています。tinychat側の問題だと思われます。
速度
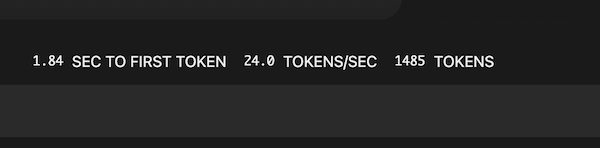
チャットの下部にでるトークンの生成スピードです。
| |
実用には程遠い感じですが4年落ちのMacBookProではこんなものでしょう。
先日、Xにも投稿した のですがexo自体LLMのトークン生成速度を上げるためのものではなく、 推論に使う層(レイヤー)をマシンごとに担当を決めて分割し、 GPUメモリを割り当てることでご家庭のマシンでも数が揃えば大規模なLLMを動かすことができる仕組みです。

各レイヤーごとのトップスピード自体はクラスタの最も速いマシンが上限になるでしょう。
使用感と課題
メリット
- 簡単なセットアップ: コマンドを実行するだけでデバイスがクラスタに参加。
- 柔軟性: 高価なハードウェアなしで大規模モデルを試せる。
- オープンソースの透明性: コードの拡張や調整が可能。
デメリット
- 性能依存: 各デバイスの性能によってクラスタ全体の処理速度が影響を受ける。
- メモリ要件: 全デバイスの合計メモリがモデルサイズをカバーする必要がある。
まとめ
exoは、手元にある複数のデバイスを活用し、高度なAI推論を実現するための魅力的なツールです。特に、家庭内のデバイスを統合することで、高価なGPUに依存せずにAIの可能性を広げられる点が注目に値します。
さらに、Apple Siliconのユニファイドメモリが、従来では動作しなかった大規模モデルを可能にする点が特筆すべきです。このユニファイドメモリの特性により、CPUとGPU間でメモリをシームレスに共有し、大規模なデータを扱う際のボトルネックが解消されます。exoとこの特性の相乗効果により、今までは諦めていた規模のモデルが動作可能となり、分散推論の新たな可能性が広がります。
今後の開発に期待しつつ、興味のある方はぜひ試してみてください。